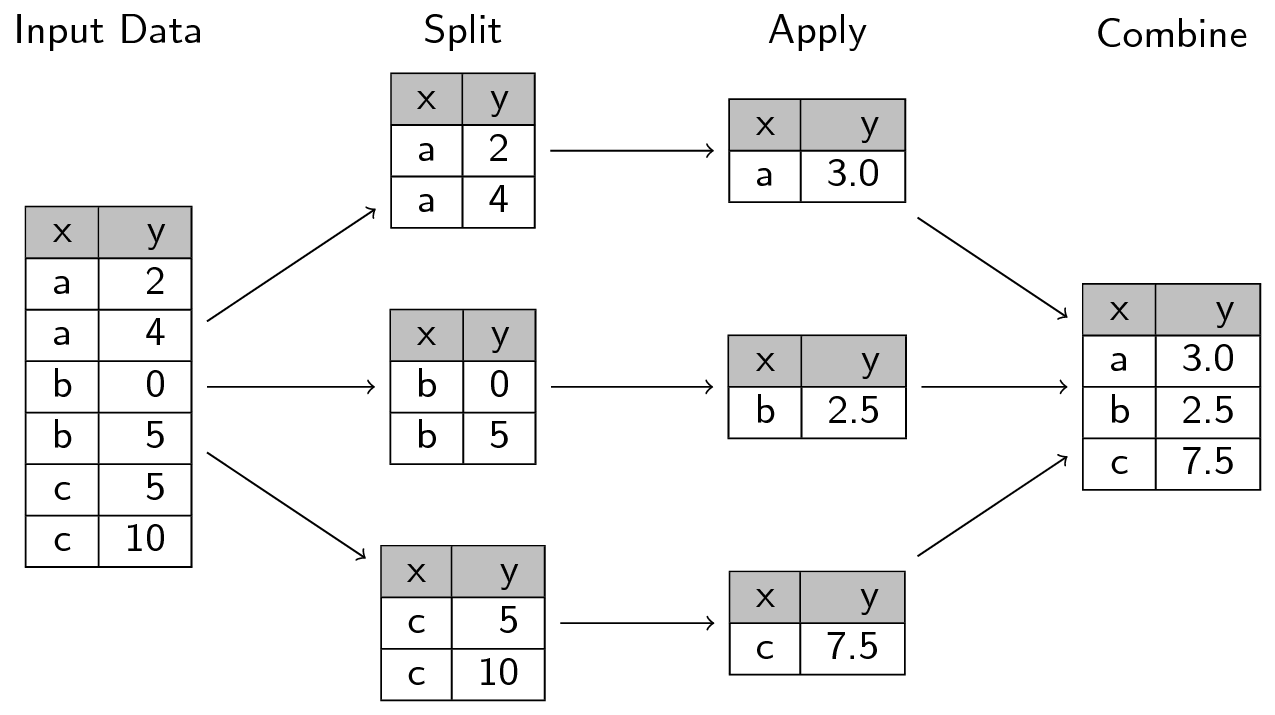
Image courtesy of swcarpentry.github.io
Image courtesy of swcarpentry.github.io
>>> sr1
a b
1 1 2
3 4
2 10 5
3 2 3
3 2
Name: c, dtype: int64
|
>>> sr2
a b
1 1 5
3 2
2 10 3
3 3 11
Name: c, dtype: int64
|
>>> sr3
a b
1 9 2
10 0 33
99 12 44
Name: c, dtype: int64
|
|---|
>>> total
a b
1 1 7
3 6
9 2
2 10 8
3 2 3
3 13
10 0 33
99 12 44
Name: c, dtype: int64
|
>>> ddf.groupby(['a', 'b']).c.sum().compute()
a b
1 1 7
3 6
2 10 8
3 2 3
3 13
1 9 2
10 0 33
99 12 44
Name: c, dtype: int64
|
>>> df.groupby(['a', 'b']).c.sum()
a b
1 1 7
3 6
9 2
2 10 8
3 2 3
3 13
10 0 33
99 12 44
Name: c, dtype: int64
|
|---|
 `sum` is rather a straight-forward calculation. What about something a bit more complex like `mean`?
```python
>>> ddf.groupby(['a', 'b']).c.mean().visualize()
```
`sum` is rather a straight-forward calculation. What about something a bit more complex like `mean`?
```python
>>> ddf.groupby(['a', 'b']).c.mean().visualize()
```
 `Mean` is a good example of an operation which doesn't directly fit in the `aca` model -- concatenating `mean` values and taking the `mean` again will yield incorrect results. Like any style of computation: vectorization, Map/Reduce, etc., we sometime need to creatively fit the computation to the style/mode. In the case of `aca` we can often break down the calculation into constituent parts. For `mean`, this would be `sum` and `count`:
$$ \bar{x} = \frac{x_1+x_2+\cdots +x_n}{n}$$
From the task graph above, we can see that two independent tasks for each partition: `series-groupby-count-chunk` and `series-groupby-sum-chunk`. The results are then aggregated into two final nodes: `series-groupby-count-agg` and `series-groupby-sum-agg` and then we finally calculate the mean: `total sum / total count`.
`Mean` is a good example of an operation which doesn't directly fit in the `aca` model -- concatenating `mean` values and taking the `mean` again will yield incorrect results. Like any style of computation: vectorization, Map/Reduce, etc., we sometime need to creatively fit the computation to the style/mode. In the case of `aca` we can often break down the calculation into constituent parts. For `mean`, this would be `sum` and `count`:
$$ \bar{x} = \frac{x_1+x_2+\cdots +x_n}{n}$$
From the task graph above, we can see that two independent tasks for each partition: `series-groupby-count-chunk` and `series-groupby-sum-chunk`. The results are then aggregated into two final nodes: `series-groupby-count-agg` and `series-groupby-sum-agg` and then we finally calculate the mean: `total sum / total count`.