---
blogpost: true
date: Dec 5, 2016
title: Dask Development Log
tags: Programming, Python, scipy
---
_This work is supported by [Continuum Analytics](http://continuum.io)
the [XDATA Program](http://www.darpa.mil/program/XDATA)
and the Data Driven Discovery Initiative from the [Moore
Foundation](https://www.moore.org/)_
Dask has been active lately due to a combination of increased adoption and
funded feature development by private companies. This increased activity
is great, however an unintended side effect is that I have spent less time
writing about development and engaging with the broader community. To address
this I hope to write one blogpost a week about general development. These will
not be particularly polished, nor will they announce ready-to-use features for
users, however they should increase transparency and hopefully better engage
the developer community.
So themes of last week
1. Embedded Bokeh servers for the Workers
2. Smarter workers
3. An overhauled scheduler that is slightly simpler overall (thanks to the
smarter workers) but with more clever work stealing
4. Fastparquet
### Embedded Bokeh Servers in Dask Workers
The distributed scheduler's [web diagnostic
page](http://distributed.readthedocs.io/en/latest/web.html) is one of Dask's
more flashy features. It shows the passage of every computation on the cluster
in real time. These diagnostics are invaluable for understanding performance
both for users and for core developers.
I intend to focus on worker performance soon, so I decided to attach a Bokeh
server to every worker to serve web diagnostics about that worker. To make
this easier, I also learned how to _embed_ Bokeh servers inside of other
Tornado applications. This has reduced the effort to create new visuals and
expose real time information considerably and I can now create a full live
visualization in around 30 minutes. It is now _faster_ for me to build
a new diagnostic than to grep through logs. It's pretty useful.
Here are some screenshots. Nothing too flashy, but this information is highly
valuable to me as I measure bandwidths, delays of various parts of the code,
how workers send data between each other, etc..
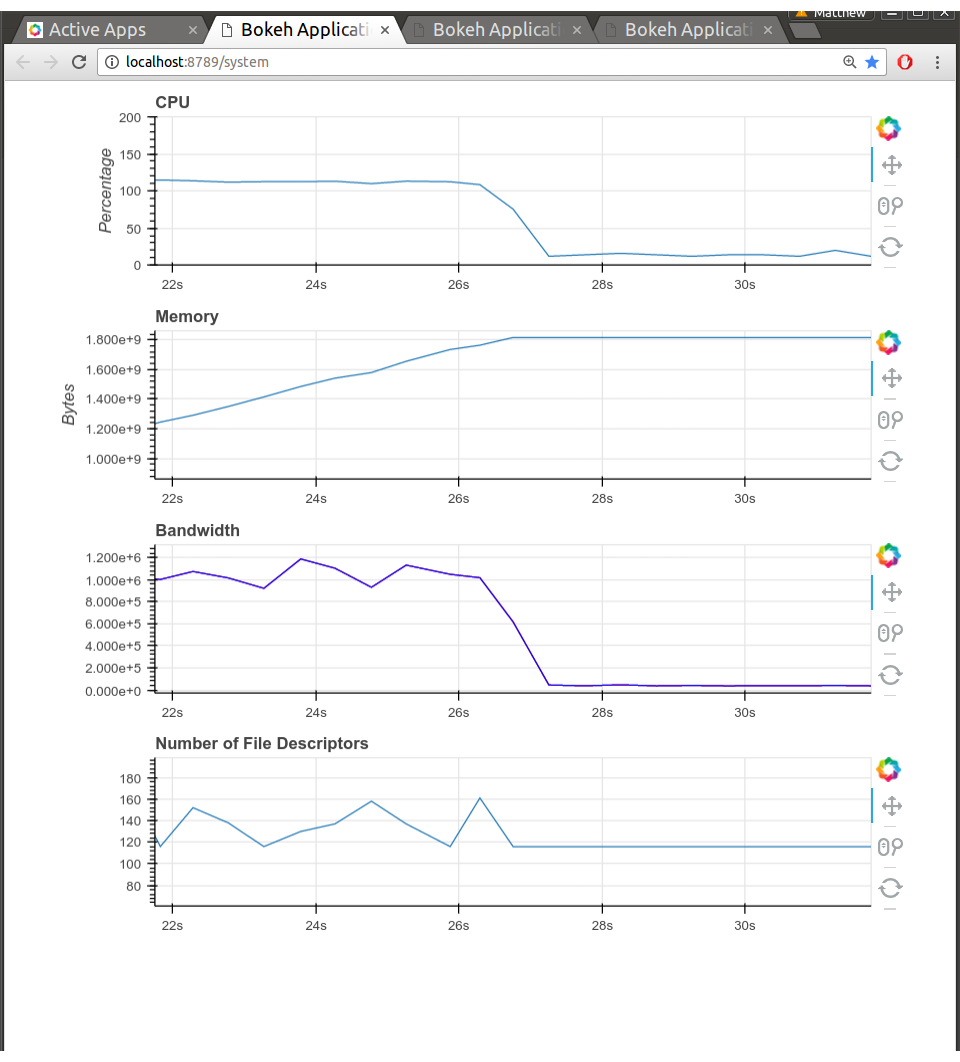
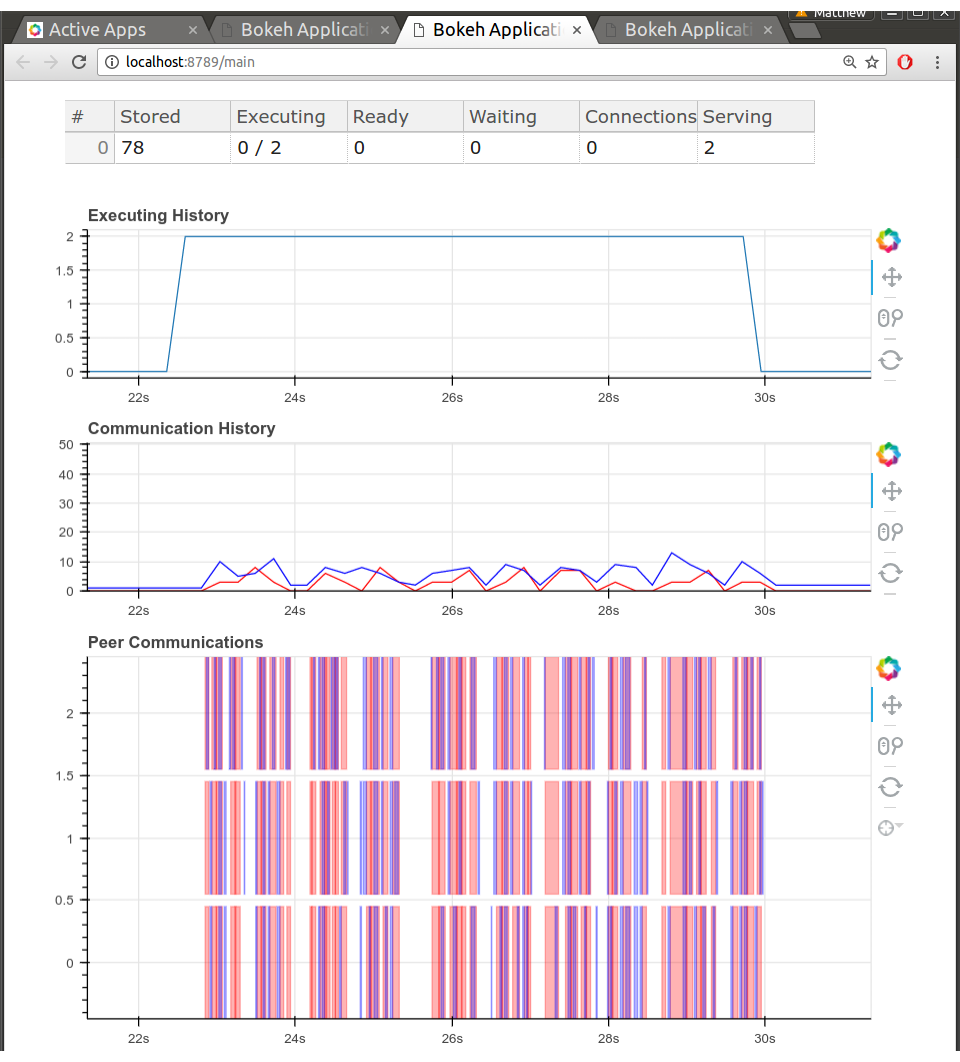
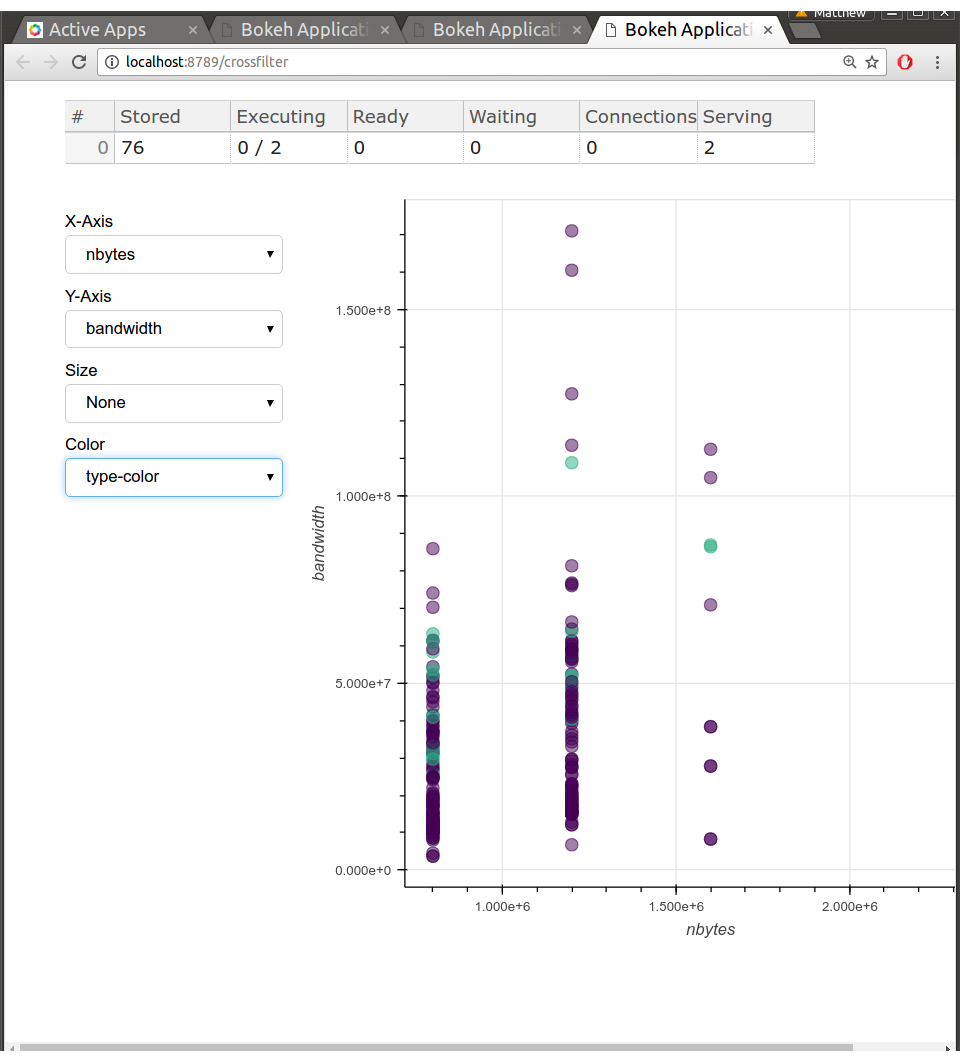 To be clear, these diagnostic pages aren't polished in any way. There's lots
missing, it's just what I could get done in a day. Still, everyone running a
Tornado application should have an embedded Bokeh server running. They're
great for rapidly pushing out visually rich diagnostics.
### Smarter Workers and a Simpler Scheduler
Previously the scheduler knew everything and the workers were fairly
simple-minded. Now we've moved some of the knowledge and responsibility over
to the workers. Previously the scheduler would give just enough work to the
workers to keep them occupied. This allowed the scheduler to make better
decisions about the state of the entire cluster. By delaying committing a task
to a worker until the last moment we made sure that we were making the right
decision. However, this also means that the worker sometimes has idle
resources, particularly network bandwidth, when it could be speculatively
preparing for future work.
Now we commit all ready-to-run tasks to a worker immediately and that worker
has the ability to pipeline those tasks as it sees fit. This is better locally
but slightly worse globally. To counter balance this we're now being much more
aggressive about work stealing and, because the workers have more information,
they can manage some of the administrative costs of works stealing themselves.
Because this isn't bound to run on just the scheduler we can use more expensive
algorithms than when when did everything on the scheduler.
There were a few motivations for this change:
1. Dataframe performance was bound by keeping the worker hardware fully
occupied, which we weren't doing. I expect that these changes will
eventually yield something like a 30% speedup.
2. Users on traditional job scheduler machines (SGE, SLURM, TORQUE) and users
who like GPUS, both wanted the ability to tag tasks with specific resource
constraints like "This consumes one GPU" or "This task requires a 5GB of RAM
while running" and ensure that workers would respect those constraints when
running tasks. The old workers weren't complex enough to reason about these
constraints. With the new workers, adding this feature was trivial.
3. By moving logic from the scheduler to the worker we've actually made them
both easier to reason about. This should lower barriers for contributors
to get into the core project.
### Dataframe algorithms
[Approximate nunique](https://github.com/dask/dask/pull/1807) and
multiple-output-partition groupbys landed in master last week. These arose
because some power-users had very large dataframes that weree running into
scalability limits. Thanks to Mike Graham for the approximate nunique
algorithm. This has also pushed [hashing
changes](https://github.com/pandas-dev/pandas/pull/14729) upstream to Pandas.
### Fast Parquet
Martin Durant has been working on a Parquet reader/writer for Python using
Numba. It's pretty slick. He's been using it on internal Continuum projects
for a little while and has seen both good performance and a very Pythonic
experience for what was previously a format that was pretty inaccessible.
He's planning to write about this in the near future so I won't steal his
thunder. Here is a link to the documentation:
[fastparquet.readthedocs.io](https://fastparquet.readthedocs.io/en/latest/)
To be clear, these diagnostic pages aren't polished in any way. There's lots
missing, it's just what I could get done in a day. Still, everyone running a
Tornado application should have an embedded Bokeh server running. They're
great for rapidly pushing out visually rich diagnostics.
### Smarter Workers and a Simpler Scheduler
Previously the scheduler knew everything and the workers were fairly
simple-minded. Now we've moved some of the knowledge and responsibility over
to the workers. Previously the scheduler would give just enough work to the
workers to keep them occupied. This allowed the scheduler to make better
decisions about the state of the entire cluster. By delaying committing a task
to a worker until the last moment we made sure that we were making the right
decision. However, this also means that the worker sometimes has idle
resources, particularly network bandwidth, when it could be speculatively
preparing for future work.
Now we commit all ready-to-run tasks to a worker immediately and that worker
has the ability to pipeline those tasks as it sees fit. This is better locally
but slightly worse globally. To counter balance this we're now being much more
aggressive about work stealing and, because the workers have more information,
they can manage some of the administrative costs of works stealing themselves.
Because this isn't bound to run on just the scheduler we can use more expensive
algorithms than when when did everything on the scheduler.
There were a few motivations for this change:
1. Dataframe performance was bound by keeping the worker hardware fully
occupied, which we weren't doing. I expect that these changes will
eventually yield something like a 30% speedup.
2. Users on traditional job scheduler machines (SGE, SLURM, TORQUE) and users
who like GPUS, both wanted the ability to tag tasks with specific resource
constraints like "This consumes one GPU" or "This task requires a 5GB of RAM
while running" and ensure that workers would respect those constraints when
running tasks. The old workers weren't complex enough to reason about these
constraints. With the new workers, adding this feature was trivial.
3. By moving logic from the scheduler to the worker we've actually made them
both easier to reason about. This should lower barriers for contributors
to get into the core project.
### Dataframe algorithms
[Approximate nunique](https://github.com/dask/dask/pull/1807) and
multiple-output-partition groupbys landed in master last week. These arose
because some power-users had very large dataframes that weree running into
scalability limits. Thanks to Mike Graham for the approximate nunique
algorithm. This has also pushed [hashing
changes](https://github.com/pandas-dev/pandas/pull/14729) upstream to Pandas.
### Fast Parquet
Martin Durant has been working on a Parquet reader/writer for Python using
Numba. It's pretty slick. He's been using it on internal Continuum projects
for a little while and has seen both good performance and a very Pythonic
experience for what was previously a format that was pretty inaccessible.
He's planning to write about this in the near future so I won't steal his
thunder. Here is a link to the documentation:
[fastparquet.readthedocs.io](https://fastparquet.readthedocs.io/en/latest/)